Advent of code in SPL - 2025 day 4
- Gabriel Vasseur

- Feb 4
- 5 min read
Updated: Feb 6
Day 4 is here.
Part 1
Let's start with the example data:

For each position, we need to count the number of neighbours. That's ok for left and right neighbours, but for the ones above and below, we need the previous and next row. That means using streamstats with current=f! But we need to use it twice now:

It kind of works, but you can see we have two problems:
we have a useless record at the top. We can simply add | search row=*
we're missing one at the bottom. All we need for that is to add a line to our data:

That's good prep. Now we need to assess each position in each row individually. That means mvexpand:

But now we've kind of lost the information of where we are in the row, which we need to figure out neighbours. We need a count that resets with every row... that means streamstats:

Every time we use a field in a by clause, we need to worry about two things:
is the field always populated? in not some data will be discarded. Here we can confidently say yes
is the field unique enough for our needs? In other words, it looks like it works here, but what if our test data had a repeated row? For instance what if row 3 and 5 were the same:

Notice how I used the cell formatting to colour the row field based on its values. Very useful to identify duplicates like here. You can see streamstats for x is doing its job but that's not the outcome we want. All we need to do is make sure we give a unique ID to each row. Again, streamstats will do that for us:

Note the extra streamstats to generate the y variable. Also note how the choice of the names of these variables is quite important to the maintainability of the code. Here x and y make a lot of sense (and are nice and short).
From now on we'll go back to the sample data (restoring line 5 to what it was). We now have all the information we have to work out the neighbours. Left and right is easy (we do have to worry about the left neighbour for the first position of the row: substr is quite happy to take 0 for a starting position but will actually treat it as if it's 1...):

For neighbours above and below, we need to worry about the extremes. It's neater to use intermediary variables:

Now that was good for debugging purposes, but of course it doesn't make sense to look at neighbours of empty spaces. So that means we need to filter on position="@". The earliest we can do that is after x has been established. Then all we have to do is collate the neighbours together and count the busy spots:

And then we just need to apply to the full challenge data:
***EDIT*** Thanks to ITWhisperer and Antony Bowesman in \#puzzles on the Splunk Community slack channel, I realised there is still a bug in this approach. Different advent-of-code users get different challenge data (presumably to avoid people copying each other's answers) and I was (un)lucky that my data didn't trigger the bug in part 1, so I was blissfully unaware, at least until part 2. The issue is that neighbour_count will be null if a roll has zero neighbours. To fix it, simply add "| fillnull value=0 neighbour_count" before the last stats. Read on part 2 to see where I finally noticed the bug the first time... ***EDIT END***
Part 1 done!
Part 2
We can continue on our previous search, but this time we need to keep all the positions (so remove | search position="@"), and rebuild the rows with the accessible rolls removed.
We'll go back to the sample data. Let's start by removing the | search position="@" and calculating if a roll is removable (we'll need that in a bit) and actually removing it if so:

Now we can rebuild the rows. We need to keep the position in orders, so we'll use stats list():
"Stats by" used to sort on the by field, but these days are long gone. So we need to sort before we join:

Now that we convinced ourselves that this is solid, we can simplify it a little:

And now we need a way to iterate this.
This means first populating a temporary lookup with our starting point. We'll refer to this now as our bootstrap search. Open a new tab for this as we'll need it several time to reset as we refine our main search:

And then using that as our starting point and updating it at the end:

Now we can run this search over and over again until the result does not change, which is kind of fun. All we have to do now is to keep track of the number of rolls being removed, which means it has to go in the lookup itself. So our bootstrap search becomes:

And in our main search we now need to keep track of how many rolls were removed (not the table command on line 8 was edited to add "removed"):

Eventstats is great to add statistical information without upsetting the events. Now we need to edit the stats function to keep removed:

The problem now is that removed is not populated for the extra line we add at the beginning, so we're losing ground at every iteration... The solution is simply to tweak append to appendpipe (note you'll need to rerun the bootstrap to start fresh):

Appendpipe is cool. It's like cloning the current search and giving it an alternative ending. Here it's like adding this:
Anyway, so now all we have to do is run the search again and again (after the bootstrap) until removed stop increasing.

So let's bootstrap with the real challenge data:

All we need to do is run our search about dozens of times to get to the answer!
Except... yes of course we run into a limit:

Each row has 140 characters, and stats's list() is limited to 100 values. We need list() to preserve the order. But we can stage it (again, rerun the bootstrap first):

This will work up to 10000 which is way more than needed here. It's kind of fun to run the search several times and see the patterns of rolls evolve. Except I noticed a bug! After a while, I noticed some lonely rolls were clearly left alone:
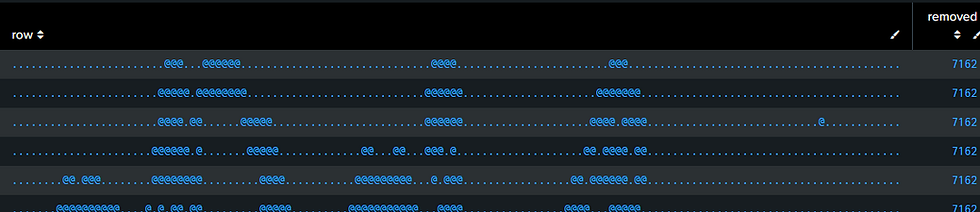
I think this is because when a roll has no neighbours, somehow neighbour_count becomes null. You can check this theory with this (notice the absence of the neighbour_count field):

Splunk is evil here. We certainly didn't see that coming. But all we need, is a fillnull:

Now it should be good.
Thankfully it only need to run about 60ish times (don't ask me how I know!), but we can go further and use mvrange and map:

The question is: how do we know how many times we need to iterate? And my answer is we don't. As far as I know, there isn't a way to predict it, and there is no such thing as a "while" loop in SPL. The only way you know is by running the above a few times and slowly increasing the range until you notice the number is not increasing. So all we did was make it less painful. Can it still be considered a fully SPL solution?
Do you know of a way to get further? Or simply a totally different way to get there?



Comments